UMEHOSHI ITA TOP PAGE
COMPUTER SHIEN LAB
[UMEHOSHI ITA]の制御で使っているIC「PIC32MX270F256B-I/SO」のフラッシュメモリには、テスト用プログラムが書き込まれいています。
これを利用したユーザー用のプログラムを「ウメ・エディットプログラム」と呼ぶことにします。
「ウメ・エディットプログラム」の開発では「umehoshiEditツール」が必要で、
その取得や最初の操作情報は、こちらを参照してください。
以下は「umehoshiEditツール」で録音で生成したumehoshiEdit.wavのファイルをpythonでグラフ化し、音の再生過程を示すものです。
[UMEHOSHI ITA]での録音と、pythonで再生
[UMEHOSHI ITA]での録音して、 umehoshiEdit.wavのファイルを作る。
umehoshiEdit.wavは、次のコードの実行で生成したものです。
実行時に、[Tools]メニューの[ADC to CSV]のチェックを入れるとファイルを作る機能があり、
これで作られたファイルです。
なおADCを扱う基本プログラムは、こちらの別ページで紹介しています。
#include <xc.h> // ADC_CN8_8K.c
#include "common.h"
#define AdrStart 0x80005000
#define AdrStop 0x80006000
__attribute__((address( AdrStart ))) void start (void);
void start()
{
_RB15 = ! _RB15;// 動作確認用のD1 LEDの点灯を反転
PR3=2499; //サンプリング周波数を 8KHzに指定するパラメタ
// (1/8000)/(1/40e6)/2-1=2499
_set_adc_mode(1, 0);// CN8のAN0端子だけでサンプリングする。出力はバイナリモード
_set_adc_exe(63, 0);// 63ブロックのサンプリング(1/8000*1024*63=8.064秒)
// 63は、上記関数を使う場合の最大値で、1の値でサンプリングバッファ1024ワード分を意味します。
AD1CON1bits.ON = 1; //ADC モジュールを有効にする(b15)
T3CONbits.ON = 1; // timer3を開始
}
__attribute__((address( AdrStop))) void stop (void);
void stop()
{
T3CONbits.ON = 0; // すぐにtimer3を停止
AD1CON1bits.ON = 0; //ADC モジュールを無効にする(b15)
IFS0CLR = _IFS0_AD1IF_MASK; // Clear ADC interrupt flag
IFS0CLR = _IFS0_T3IF_MASK; // Clear the timer3 interrupt status flag
}
上記の実行で、16bit符号モノラルで8KHzビットレートにより、8.064秒間の録音したサンプリングファイル「umehoshiEdit.wav」を
「自身のミュージックのフォルダ」の中に生成します。
pythonで umehoshiEdit.wavのファイルを再生して、グラフ化する。
上記実行で作られた umehoshiEdit.wavのファイルが、カレントディレクトリに存在する前程で、再生後にグラフ化するPythonコード例を示します。
import numpy as np
import wave
WAV_FILE="umehoshiEdit.wav" # 再生、プロット対象
wavefile = wave.open(WAV_FILE, "r")
framerate = wavefile.getframerate() # フレームレート(1秒間のデータ出力数)
print("フレームレート:", framerate/1000, "KHz")
nchannel=wavefile.getnchannels()
print("チャンネル数:", nchannel)
sampwidth=wavefile.getsampwidth()
print("サンプル幅数:", sampwidth)
nframes = wavefile.getnframes() # フレーム数(データの個数)
print("nframes:" , nframes) # 実行例: nframes: 80000(10秒)
buffer = wavefile.readframes(nframes) # ファイルからフレーム数の読み取りバイナリのデータを返す。
wavefile.close() # ファイルを閉じる
print("----- 以上で、.wavファイルをbufferに読み込み、それをここより再生する -----")
import pyaudio # 録音や再生に使う ここより再生
audio = pyaudio.PyAudio()
format=audio.get_format_from_width(sampwidth) # ストリームを読み書きするときのデータ型
stream = audio.open(format=format,channels=nchannel,rate=framerate,output=True)
stream.write(buffer) # ストリームへの書き込みで音が出力される。
print("上記再生音のデータバイト数:", len(buffer) )
stream.stop_stream()
print("----- 上記再生データをグラフにプロットする -----")
import matplotlib.pyplot as plt
xn= np.arange(0, len(buffer)/2 )
ys = np.frombuffer(buffer, dtype="int16")
# 上記 buffer のバイナリが、16bit 整数(リトルエンディアン)である前提で、numpy生成した
plt.plot( xn, ys ) # samplingデータysをプロット
plt.show()
上記実行結果例を示します。
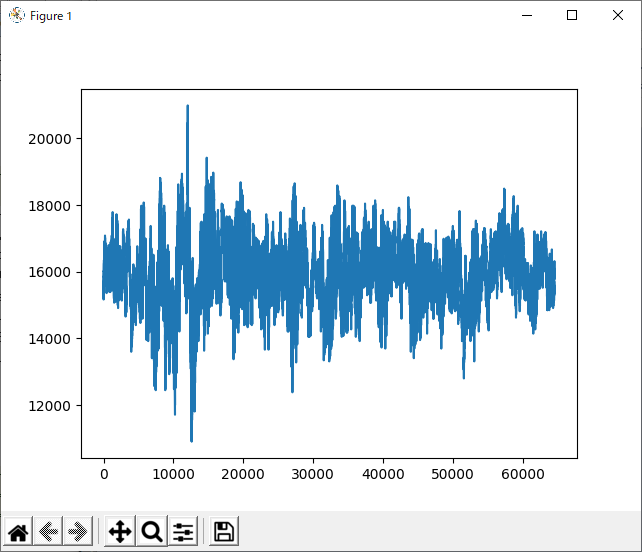
C:\Users\work\Music>python ADC_CN8_8K.py
フレームレート: 8.0 KHz
チャンネル数: 1
サンプル幅数: 2
nframes: 80000
----- 以上で、.wavファイルをbufferに読み込み、それをここより再生する -----
上記再生音のデータバイト数: 129024
----- 上記再生データをグラフにプロットする -----
上記 wavefile.getnframes()# フレーム数(データの個数)で得られる80000と、
buffer = wavefile.readframes(nframes)で得られる129024が合わないことが分かった。
再生音のデータバイト数: 129024は16bitなので129024/2=64512と80000が一致していない。
これは、wavefile.getnframes() が実際にファイルに格納されるデータ個数と違う場合があると予想される。
wavefile.readframesを使うことで、引数が80000と多くても実際に存在するデータが取得されるようだ。
よって、次にwavefile.readframes(1024)で読む繰り返しして、再生に対して、リアルタイムプロットのが変化する手法を検討する。
pythonで umehoshiEdit.wavのファイルを1024フレームごと再生して、グラフをアニメーション化する。
umehoshiEdit.wav(符号無し16bit符号モノラル,8KHz)のファイルが、カレントディレクトリに存在する前程で、
そのファイルから1024フレームごとに、『読み取って音の再生と、そのグラフ表示』を繰り返すPythonコード例を、以下に示します。
import numpy as np
import wave
WAV_FILE="umehoshiEdit.wav" # 再生、プロット対象
import matplotlib.pyplot as plt
def plotting( xlist, ylist ): # xlist、ylistでプロットして1e-20秒待つ
lines.set_data(xlist, ylist) # 描画データを更新する
ax.set_xlim((xlist.min(), xlist.max()))
plt.pause(1e-20) # ブロックするplt.show()の代わりに描画している。
wavefile = wave.open(WAV_FILE, "r")
framerate = wavefile.getframerate() # フレームレート(1秒間のデータ出力数)
print("フレームレート:", framerate/1000, "KHz")
nchannel=wavefile.getnchannels()
print("チャンネル数:", nchannel)
sampwidth=wavefile.getsampwidth()
print("サンプル幅数:", sampwidth)
nframes = wavefile.getnframes() # フレーム数(データの個数)
print("nframes:" , nframes) # 実行例: nframes: 80000(10秒)
import pyaudio # 録音や再生に使う。再生オープン
audio = pyaudio.PyAudio()
format=audio.get_format_from_width(sampwidth) # ストリームを読み書きするときのデータ型
stream = audio.open(format=format,channels=nchannel,rate=framerate,output=True)
print("----- wavファイル1024ワードをbufferに読み込みそれを再生する繰り返し -----")
fig, ax = plt.subplots(1, 1) # FigureとAxes object取得
plt.get_current_fig_manager().window.wm_geometry("+100+50") # (100,50)位置に表示
lines, = ax.plot([0,0], [1024, 25000]) # matplotlib.lines.Line2D取得
xlist=np.arange(1024) # x軸プロット用の集合
while True:
buffer = wavefile.readframes(1024) # 1024フレーム読み取る
stream.write(buffer) # ストリームへの書き込みで音が出力される。
# print("上記再生音のデータバイト数:", len(buffer) )
if len(buffer) != 1024*2: break
ylist = np.frombuffer(buffer, dtype="int16")
plotting( xlist, ylist ) # プロット描画
xlist += 1024
wavefile.close() # ファイルを閉じる
stream.stop_stream()
plt.show()
16bitのバイナリーで1024個のフレームごとに、『読み取り、再生、グラフ表示』を繰り返しています。
これは将来的に、連続的で録音で取得する情報を、無限に再生すること行う目標のために作ったコードです。
最終的には、USBで接続される[UMEHOSHI ITA]で録音して、そのUSB受信情報で『読み取り、再生、グラフ表示』させます。
上記のコードはその前提で、連続的で録音で取得する箇所を、ファイルからの呼び出しにした検証用のコードです。
なお、グラフ化に関しては、1024個のフレームごと表示が繰り返されるので、グラフのアニメーション表示になっており、
その1024フレーム1回の表示用として、plotting関数を定義して使っています。
この実行で得られるグラフのアニメーション表示例のイメージを下に示します。
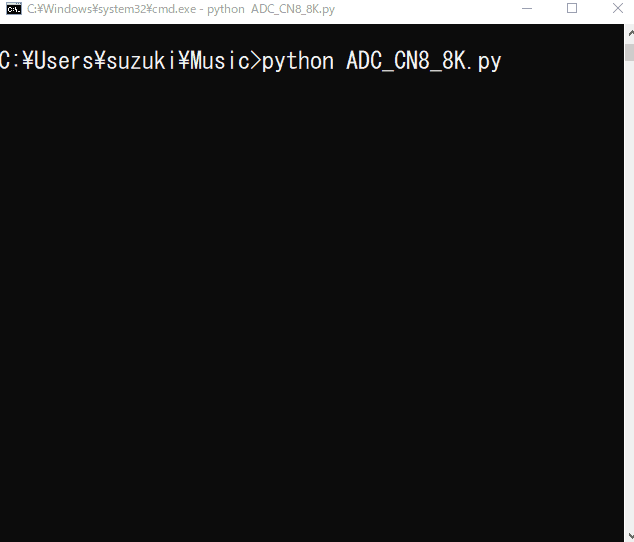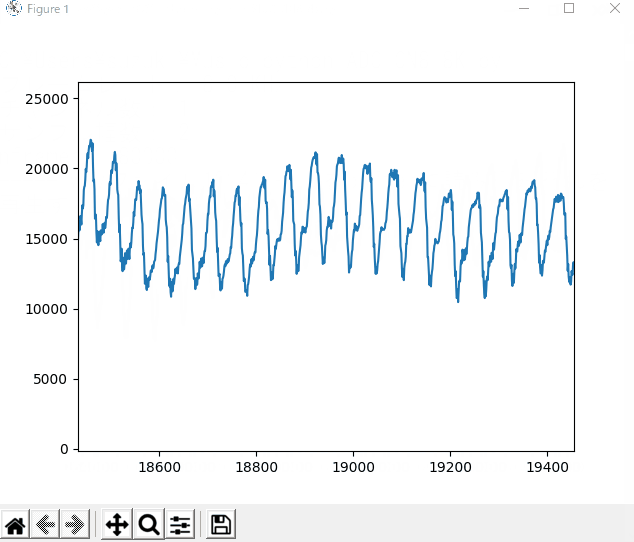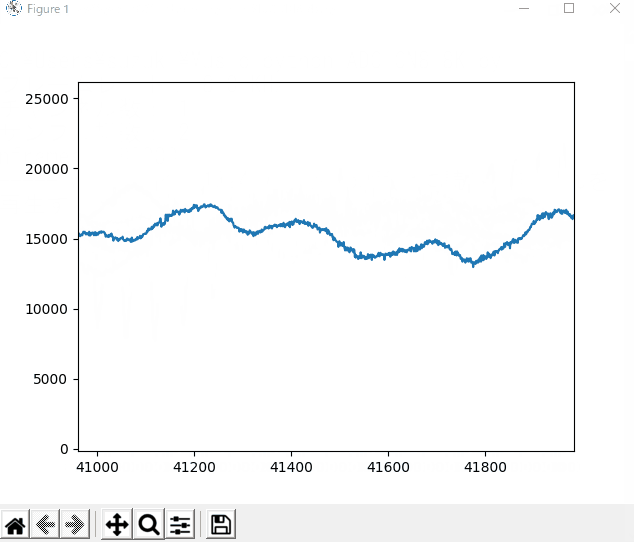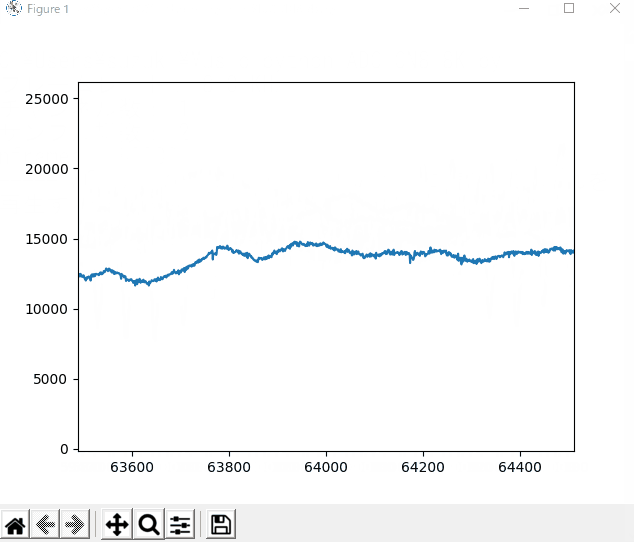
録音時は、「イチ、ニィ、サン、シィ、ゴォ、ロク、シチ、ハチ」、「ニィ、ニィ、サン、シィ」と発音しました。
連続録音再生に挑戦 (独自コーディックの模索)
UMEHOSHI ITA基板のPIC32MX270F256B-50I/SPのADC能力は逐次比較の10-bit(1MSPS)です。
録音には向かないけど、前述のサンプリング周波数を8KHzから16Hzに上げて連続録音・再生すること挑戦します。
しかし、USB CDC(Communication Device Class)を介して行うので、転送能力がかなり足りない現状です。
対策として、録音データを圧縮して送信する方法があり、挑戦した内容です。
これは、基板の1024ワード送信に合わせた可逆圧縮の独自コーディックを模索する内容です。
16Bit、16KHzのサンプリングで、1024ワードの.binファイルを作る
まず、目標のバイナリファイルを作る。テスト用として1KHzの正弦波のファイル(16bit16KHz_1KHz1024sin.bin)を作る。
これは、圧縮対象の実験用ファイルとして作成したサウンド生ファイルです。
# 16KHzで16Bitのサンプリングでリトルエンディアン符号無しの1000Hz正弦波データを1024ワード並ぶファイルを、16Bit_1KHz_1024_sin.binの名前で作る。
# このファイルのバイト数は、1024ワードなので、2048byteになる。全体の時間=(1/16KHz)*1024=(1/16e3)*1024=0.064秒
# 振幅は、0~1024で変化する生成にする。
import math
import numpy as np
sample_rate = 16000 # サンプリングレート
frequency=1000
singen=lambda sec : math.sin( math.pi * 2 * frequency * sec )*(2**15-1) + (2**15-1)
# singen=lambda sec : math.sin( math.pi * 2 * frequency * sec )*(2**15-1)*(sec/0.065) + (2**15-1) # ★ 徐々に大きくする
ts = [ 1/sample_rate * t for t in range( 1024 )]
ys = [ singen( t ) for t in ts ]
# ys = [ singen( t )+int(np.random.uniform(-5,5)) for t in ts ] # ★ ノイズを加える
bs=np.array(ys, np.uint16)
buffer=b''.join(bs) # バイナリに変換
with open("16bit16KHz_1KHz1024sin.bin","wb") as fw:
fw.write( buffer )
# 確認用の表示
import matplotlib.pyplot as plt
plt.plot( ts, ys )
plt.show()
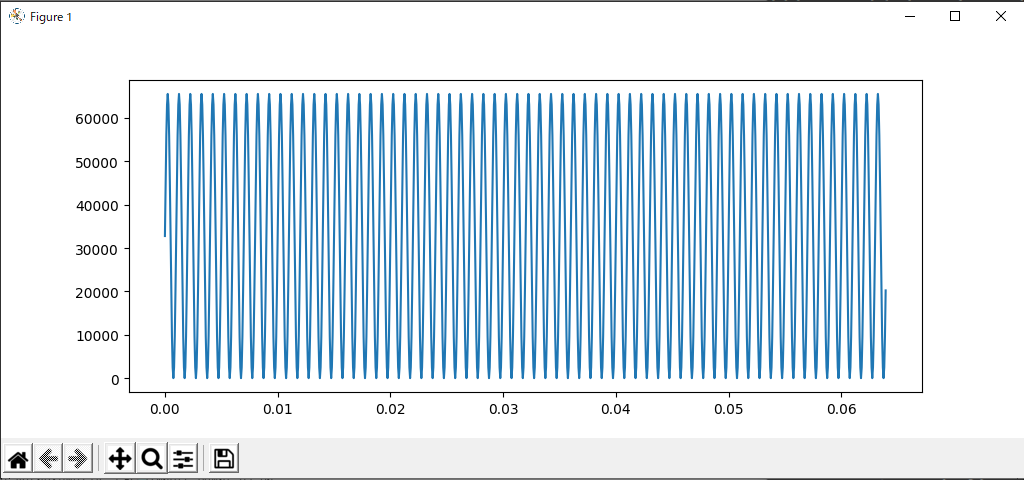
上記で生成されたファイルは、uint16が1024個のが並ぶ2048byteサイズで、
ADCの出力データを模擬したデータです。
そして、このファイルの圧縮を後で検討します。
なお、このファイルをWindow標準圧縮で.zipにすると、2048byteが237byteになりました。
圧縮元のファイルが正確な算術による正弦波なので、同じデータを多く含むからではと思いますが、この圧縮率はビックリ!
チョットな別のサンプルを作って確かめようとしたコードが、上記ソースの次のコメント部分です。
# singen=lambda sec : math.sin( math.pi * 2 * frequency * sec )*(2**15-1)*(sec/0.065) + (2**15-1) # ★ 徐々に大きくする
このコメント外して、このコードを有効にすると、Window標準圧縮で.zipに変換した場合のサイズが、2160byteになりました。
予想の通りで、同じデータをほとんど含まないファイルは、圧縮できないという結果です。
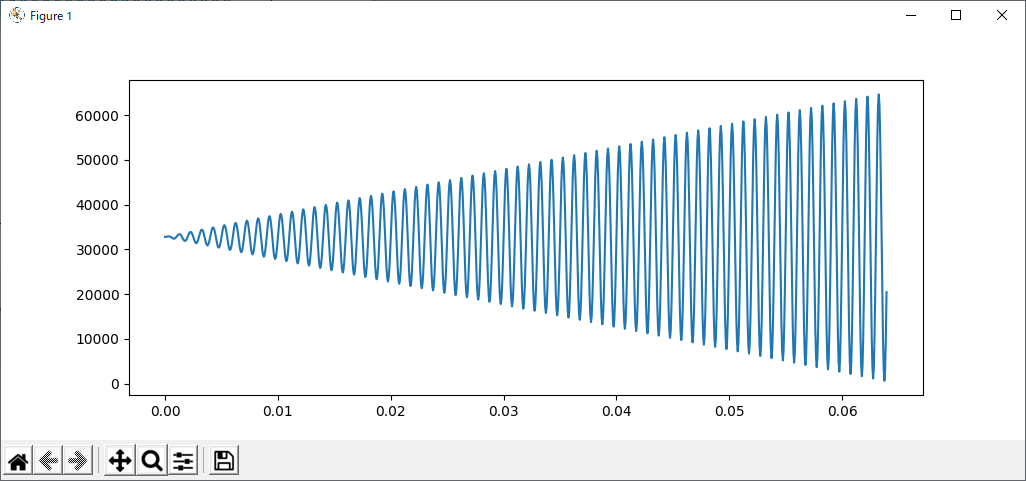
なお、次のコードを有効にして乱数で雑音(-5から+5)を加えてみました。
# ys = [ singen( t )+int(np.random.uniform(-5,5)) for t in ts ] # ★ ノイズを加える
この結果の.zipに変換したファイルサイズ例では、2048byteが2198byteになりました
この時の波形を以下に示します。(乱数を加えていますが、見た目は加えていない場合と変わりません。これが人間の識別というものですね)
16Bit、16KHzのサンプリングが1024ワード並ぶだけのbinから、.wavファイルを作って検証
上記で作成した、ADC出力の模擬ファイルの検証用の、.wavファイルに変換するプログラムです。
ADC出力イメージのバイナリイメージファイル(16bit16KHz_1KHz1024sin.bin)を読み取り、
その16bit符号無し 16KHz 1024 ワード(リトルエンディアン)のバイナリから、"16bit16KHz_1KHz1024sin.wav"を作り、
作成データの検証をする。
参考: https://docs.python.org/ja/3/library/wave.html
import wave
buffer=b''
fr=open("16bit16KHz_1KHz1024sin.bin","rb")
while True:
bs = fr.read(1) # 可能な限り読み取る
if len(bs) != 1 : break
#bs = bytes([bs[0] - 2**7]) # リストを指定して、bytesへ変換
buffer += bs
fr.close()
# 以上のデータ読み取りまでは、他の言語でもできるようにnumpyを使わなかった。
# buffer のbytesがuint16を、int16に変換する。
import numpy as np
ys2 = np.frombuffer(buffer, dtype="uint16")
ys2=ys2.astype(int)
ys2=ys2-(2**15-1)
ys2=ys2.astype(np.int16)
plt.plot( ts, ys2 )
plt.show()
buffer=b''.join(ys2) # バイナリに戻す
# int16が1024個並ぶbytesのbufferから、"16bit16KHz_1KHz1024sin.wav"を生成する。
import wave
''' barray の16bitリトルエンディアンバイト列から、未圧縮でpathのサウンドファイルを作る'''
wavefile = wave.open("16bit16KHz_1KHz1024sin.wav", 'wb') # waveファイルをバイナリ保存用として開く。
wavefile.setnchannels(1) # モノラル(単一の音信号)
wavefile.setsampwidth(2) # 2byteのデータ群と録音する指定
wavefile.setcomptype("NONE", "not compressed") # comptype, compnameの非圧縮指定
wavefile.setframerate(16000) # サンプリングレート
#wavefile.writeframes(buffer) # 上記で設定した属性で、ファイルに出力
wavefile.writeframesraw(buffer) # 上記で設定した属性で、ファイルに出力
print(f"-----{path}ファイルの情報-----")
print('type: ', type(wavefile))
print('チャンネル数:', wavefile.getnchannels()) # モノラルなら1,ステレオなら2
print('サンプル幅:', wavefile.getsampwidth()) # バイト数 (1byte=8bit)
print('サンプリング周波数:', wavefile.getframerate()) # CDは44100Hz
print('フレーム数:', wavefile.getnframes()) # サンプリング周波数で割れば時間
params=wavefile.getparams()# 上記+αのパラメータクラスを返す
print('パラメータ',type(params) ,":", params)
wavefile.close()
上記で出来上がった、wavファイルをAudacityPortable.exeで、.wavのしての確認を音を鳴らして検証した。
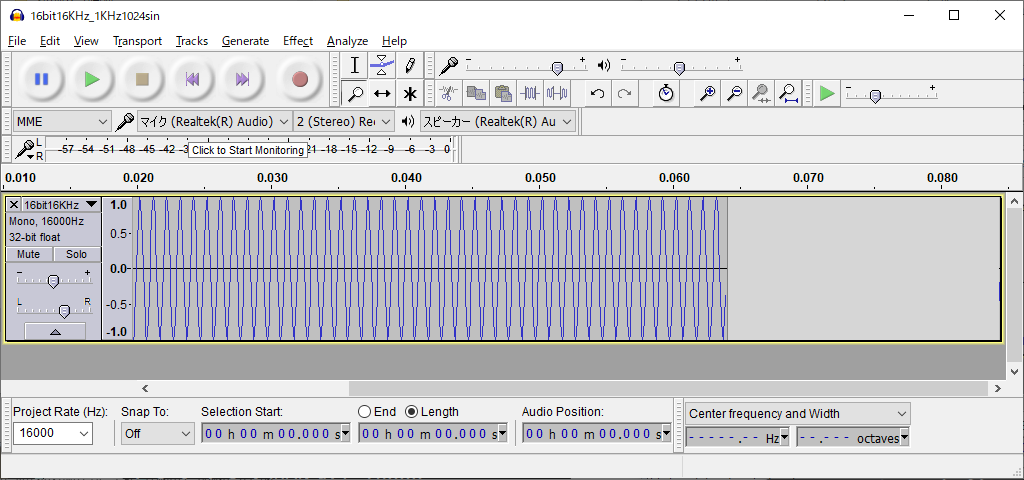
"16bit16KHz_1KHz1024sin.bin"バイナリ(2048byte)を、.wavに変換しているが、そのサイズは2092byteになった。
これをWindow標準圧縮で、.zipに変換すると280byteに圧縮された。
またmp3に変換すると2880 byteに増え、AACに変換すると1769byteに減った。
これはAudacityの[Export Audio]のメニュー操作で行って得た値で、正確な能力差でないかもしれない。
.
圧縮アルゴリズムの検討
上記プログラムで作成したファイル("16bit16KHz_1KHz1024sin.bin")を圧縮する検討です。
これは、16bitの2byteが1024個並ぶ情報で、1024*2=2048byteのサイズです。
しかし、UMEHOSHI ITA基板のPIC32MX270F256B-50I/SPのADC能力は逐次比較の10-bit(1MSPS)なので、1つのデータは10bitです。
よって10bitをを2byteで送るのでなく、1byteと1/4byteで送れば、より少ないbyteで送ることができます。
4個(8byte)であれば、10*4/8=5byteで送るということです。
つまり、各バイト要素のビット空きがないように詰めて記憶するということです。
これで10bit 1024個であれば、2048bytが1280byteに圧縮できます。
またデータ量が少なければ、もっと少ないビット長で詰めて送信することもできます。
例えば、4、7、2の3つのデータを3bit、3bit、2bitに詰めて記憶すると、
0b100, 0b111, 0b10の3つは0b10111100の1byteに圧縮できたことになります。
このように、個々のデータに必要なビットを各バイト要素に詰める機能のクラスを
以下で作りました。
(下記コードをコピーしてbitbyte.pyを作り、自由にご利用していただいて結構です。
可能な限り下記内容の"bitbyte.py"のモジュールを作って、ご利用ください。)
''' bitbyte.py
これは、個々のデータに必要なビットを各バイト要素に詰めて使うための機能です。
bit列をbyte列に変換、またはその逆変換用モジュール
このbit列とは、(unsigned int , ビット数)の集合です。
「UMEHOSHI ITA」基板(https://manabu.quu.cc/up/ume/)で、
USB転送能力を補うために作ったものですが、他にも利用できるでしょう。
'''
class BitByte:
def __init__(self, byte_buf=None):
''' byte_bufがNoneでビット列構築用で、バイト列を指定した場合はビット列復元用 '''
self.byte_buf = bytearray(byte_buf) if byte_buf else bytearray(0)
self.bit32=0 # bit設定の作業用変数
self.bitCount=0 # 上記への記憶数 8を超えた毎に処理
self.bitSize=0 # データのビットサイズ
if byte_buf!=None: self.idx = 0 # 取り出す時の位置を記憶 (20221113変更)
#
def setdata(self, data, bitSize): # bit列をbyte列に変換 ビット列構築用で使う。
'''bitSizeのビット数で、dataを記憶 (ビット列復元用オブジェクトで使えません。)'''
bitmask = (1<<bitSize)-1
if data > bitmask : raise Exception(f"{data} does not fit in {bitSize} bit")
self.bit32 |= data << self.bitCount
self.bitCount += bitSize
#print(f"{self.bit32:032b}")
while self.bitCount >= 8:
self.byte_buf.append(self.bit32 & 0x0ff)
self.bit32 >>= 8
self.bitCount-=8
#
def getbinary(self): # ビット列構築用で使う。
'''self内に記憶した全てのデータ(byte_bufとbit32)のバイナリ列を返す '''
rtn = self.byte_buf.copy()
if self.bitCount > 0:
rtn.append(self.bit32 & 0x0ff)
return rtn
#
def getdata(self,bitSize): # ビット列復元用で使う。
'''bitSizeのビット数の値を取り出して返す(ビット列構築用オブジェクトで使えません。) '''
bitmask = (1<<bitSize)-1
while self.bitCount < bitSize:
self.bit32 |= self.byte_buf[self.idx] << self.bitCount
self.bitCount += 8
self.idx += 1
val = self.bit32 & bitmask
self.bit32 >>= bitSize
self.bitCount -= bitSize
return val
#
def print(self): # ビット列構築,ビット列復元 のオブジェクトで使う。
''' 記憶内容を2進列で表示 '''
a = self.getbinary()
for i,e in enumerate(a):
print(f"{int(a[i]):08b}", end=" ")
print(" 要素数:", len(a))
#
@property
def bit_size(self): # ビット列構築用で使う。
''' 記憶しているbit数 '''
return (len(self.byte_buf)<<3)+self.bitCount # 記憶 bit数
#
def padding(self): # ビット列構築用で使う
''' bit_sizeサイズが、丁度byteに達するように0で埋める'''
if self.bitCount != 0:
self.setdata(0, 8-self.bitCount) # bit列をbyte列に変換
#
def add_bitbyte(self, byte_buf, size): # ビット列構築用で使う
''' self のデータの後ろに、sizeのビット長のbyte_bufバイナリを追加する '''
bt=BitByte(byte_buf)
while size >= 8 :
data=bt.getdata(8)
self.setdata(data,8)
size-=8
#
data=bt.getdata(size) # 残りビットをコピー
self.setdata(data,size)
if __name__ == '__main__': # --チョット確認--
d=BitByte() # 圧縮用(ビット列構築用)
d.setdata(0b100, 3) #3ビットで記憶
d.setdata(0b111, 3)
d.setdata(0b010, 2) #2ビットで記憶
a=d.getbinary() # 圧縮したバイト列取得
d.print() # 10111100 要素数: 1が表示
#
d2=BitByte(a)# 解凍用(ビット列復元用)
print(d2.getdata(3)) #取り出して4が表示
print(d2.getdata(3)) #7が表示
print(d2.getdata(2)) #2が表示
上記の実行例を以下に示します。(4,7,5を1byteに記憶後、復元して表示しています。)
10111100 要素数: 1
4
7
2
下記プログラムは、BitByteの動作を検証用プログラムです。
from bitbyte import BitByte
print("------詳細確認-まずは14個のintを記憶させる--------")
bits = [ v for v in range(2, 16) ]
datas = [ 2**v-1 for v in bits]
ts=list(zip(datas, bits))
print(ts)
d=BitByte() #圧縮用
for data , bit in ts: d.setdata(data, bit)#dataをbitで記憶
print(d.getbinary())
d.print() # 確認表示
print(f"56bitを{len(d.getbinary())}bitで記憶した。以下で取り出しを行う")
d2=BitByte(d.getbinary()) #圧縮用
ts2=[]
for data , bit in ts:
v = d2.getdata(bit)
ts2.append( (v, bit) )
print(f"bit:{bit:3} {v}" )
print(ts2)
print(f"ts==ts2の検証(元データと復元の比較。成功?):{ts==ts2} ")
上記の実行例です。最初に表示されるタプル列は、(データ,ビット長)が並んぶ検証データ群です。
例えば、(7, 3)であれば、符号なし7の値を、3ビットで記憶する指示データです。
これらを順次にバイト列に詰めて出来たバイト列を表示後、取り出して表示して合っているか検証しています。
------詳細確認-まずは14個のintを記憶させる--------
[(3, 2), (7, 3), (15, 4), (31, 5), (63, 6), (127, 7), (255, 8), (511, 9), (1023, 10), (2047, 11), (4095, 12), (8191, 13), (16383, 14), (32767, 15)]
bytearray(b'\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\xff\x7f')
11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 11111111 01111111 要素数: 15
56bitを15bitで記憶した。以下で取り出しを行う
bit: 2 3
bit: 3 7
bit: 4 15
bit: 5 31
bit: 6 63
bit: 7 127
bit: 8 255
bit: 9 511
bit: 10 1023
bit: 11 2047
bit: 12 4095
bit: 13 8191
bit: 14 16383
bit: 15 32767
[(3, 2), (7, 3), (15, 4), (31, 5), (63, 6), (127, 7), (255, 8), (511, 9), (1023, 10), (2047, 11), (4095, 12), (8191, 13), (16383, 14), (32767, 15)]
ts==ts2の検証(元データと復元の比較。成功?):True
検証例2:
例えば10bitのADコンバータで得られた10bit圧縮BitByteが2つ存在する場合、
これを結合して一つのBitByteにまとめてから送るケースを想定して、それを検証する例です。
[ 8 , 9 , 10 ] の各要素を10ビットで詰めて記憶してできるが30bit長のBitByteオブジェクトのbtです。
[ 1 , 2 , 3 ] の各要素を10ビットで詰めて記憶してできるが30bit長のBitByteオブジェクトのbt2です。
btに、bt2を結合して、60bit長にしてから、順次データ取り出して表示しています。
from bitbyte import BitByte
bt=BitByte() # ビット列構築用オブジェクト生成
datas=[ 8 , 9 , 10 ] # 記憶対象のデータ群
for value in datas:
bt.setdata(value,10) # valueを10bitで記憶
bt2=BitByte() # ビット列構築用オブジェクト生成
datas=[ 1 , 2 , 3 ] # 記憶対象のデータ群
for value in datas:
bt2.setdata(value,10) # valueを10bitで記憶
bt.add_bitbyte(bt2.getbinary(), bt2.bit_size) # bt2をbtに追加
bt = BitByte( bt.getbinary() ) # ビット列復元用オブジェクト生成
print(bt.bit_size,"bit")
for n in range(6):
print(bt.getdata(10))
上記実行結果です。2つ結合したBitByteのbit_sizeは64bitです。(これは6つのデータを8byteに詰めて記憶しています)
64 bit
8
9
10
1
2
3
利用例:
符号なしデータとして4個の6ビット長データを3byteに圧縮記憶させるコード例
from bitbyte import BitByte
bt=BitByte()
datas=[ 8 , 9 , 10 , 12 ] # 記憶対象のデータ群
for value in datas:
bt.setdata(value,6) # valueを6bitで記憶
bt.print()
# 01001000 10100010 00110000 要素数: 3 のbyteに圧縮している意味の表示
compressed_data=bt.getbinary()
print(compressed_data) # bytearray(b'H\xa20') の表示
with open("compressed.bin" ,"wb") as fw: #バイナリ3byteのファイル保存
fw.write(compressed_data)
上記"compressed.bin"の3byteを解凍して4byteを得る
from bitbyte import BitByte
with open("compressed.bin" ,"rb") as fr: #バイナリ3byteのファイル読み込み
compressed_data=fr.read(3)
bt=BitByte(compressed_data)
datas=[] # 復元データ群の記憶用リスト
for n in range( len(compressed_data) * 8 // 6 ):
datas.append( bt.getdata(6) ) # 6bit分を取り出して記憶
print(datas) # [8, 9, 10, 12]を表示
以上で圧縮の可能性を示しましたが、実際に汎用的に使うためには、記憶した情報に応じて、記憶ビット長を可変長にして
より少ないビット長で記憶させなければならないでしょう。
2~31のビット長で、「符号なし」と「符号あり」のデータ変換関数
bitsizeの指定ビット長において、
符号ありvalを、符号なしに変換する次の関数の「 to_uint(val, bitsize) 」と、
符号なしuValを、符号ありに変換する関数の「 to_int(uVal, bitsize) 」の関数定義と操作例を示します。
# bitsizeビット長の符号ありvalを、符号なしに変換する関数の検証
def to_uint(val, bitsize):
return val & (1<<bitsize)-1
def to_int(uVal, bitsize):# bitsizeビット長の符号無しuValを符号ありに変換
sign_bit=1<<(bitsize-1)
return uVal if uVal < sign_bit else uVal-(sign_bit<<1)
print( to_uint(-8, 4) ) # 8の表示
print( to_uint(-1, 4) ) # 15の表示
print( to_uint(-1, 8) ) # 255の表示
print( to_int(0b100, 3) ) # -4の表示
print( to_int(0b111, 3) ) # -1の表示
#n=5;a=[print(f"{v:4}={to_uint(v,n):05b}") for v in range(-2**(n-1),2**(n-1))] # 検証用
#n=5;a=[print(f"{v:05b}={to_int(v,n):4}") for v in range(2**n)] # 検証用