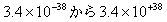 の範囲を意味します。
の範囲を意味します。floatやdoubleは、浮動少数点の記憶方法で、 これに対応した表記が使えるわけです。例えば 123.0 と 1.23e+2 の記述は同じ値のデータを表現しているものとなります。
そしてprintfで%eを使えば、指数表現の表示が得られます。scanfの%fや%lfでは 123や123.0 や 1.23e+2 の入力が可能です。
基本となるデータ型を大きく分類すると、整数(int型など)と実数(double型など)に分けられますが、 詳細に分類すると、次のように分類できます。
| 基本分類 | 型名 | size | 備考 (記憶可能な範囲) | フォーマット printf | フォーマット scanf |
|---|---|---|---|---|---|
| 整数 | unsigned char | 1byte | 0〜255 | %u %c %x %o | %c |
| signed char | 1byte | -128〜127 | %d %c %x %o | %c | |
| char | 1byte | コンパイラ依存 | %d %c %x %o %u | %c | |
| unsigned short int | 2byte | 0〜65535 | %hu %hc %hx %ho | %hu %hx %ho | |
| signed short int | 2byte | -32768〜32767 | %hd %hc %hx %ho | %hd %hx %ho | |
| int | コンパイラ依存 | コンパイラ依存 | %d %c %x %o %u | %d %x %o %u | |
| unsigned long int | 4byte | 0 〜 4294967295 | %lu %lc %lx %lo | %lu %lx %lo | |
| signed long int | 4byte | -2147483648 〜 2147483647 | %ld %lc %lx %lo | %ld %lx %lo | |
| 実数 | float | 4byte | 単精度 3.4e +/- 38 (7 桁) | %f %e | %f %e |
| 実数 | double | 8byte | 倍精度 1.7e +/- 308 (15 桁) | %f %f | %lf %le |
以上のようにたくさんある理由は、コンピュータのメモリ資源をより有効に使うためと言えます。
また同時に、『データをメモリへどのような規則で記憶するかを指定するもの』がデータ型なのです。
例えば、signed long int d;と変数宣言した場合、d = 123;の表現は、
dが(signed long int)型なので、その4byteの記憶域を整数の記憶方法に従って、
00000000000000000000000001111011へ変更する指示を書いていることになります。
しかし、float d;と変数宣言した場合、d = 123;の表現は、
dが(float)型なので、その4byteの記憶域をfloat型の記憶方法に従って、
01000010111101100000000000000000(←123をfloat型で表したバイナリデータ)へ変更する指示を書いていることになります。
このように型が異なれば、同じ4byteを記憶する場合でも全く違う記憶方法になります。
この仕組みは、=演算子によって行われているのですが、
これ以外の演算子も、扱うデータ型の種類によって全く異なる結果になる場合があります。よって、
表現しているのが何型かなのを十分注意しなければなりません。
たくさんの型がありますが、通常よく使うのはchar、int、doubleでしょう。
しかし、上記ではコンパイラ依存になっている部分があり、それについて説明します。
まずchar型ですが、これはsigned charを意味するコンパイラが多いようです。しかし
コンパイルする時の指定で、unsigned charへ変更できるのが一般的です。
次にint型ですが、これは作っている作品を動かすコンピュータが
最も効率よく動くCPUのレジスタサイズになっています。
つまり16bitCPU上で動く作品用であれば2byteの整数になり、
32bitCPU上で動く作品用であれば4byteの整数になります。
CPUのレジスタサイズは変化しており、これもコンパイルする時の指定で変更できるものがあります。
パーソナルコンピュータにおいて、1985年頃までのCPUは16bitで、そのコンピュータ用のCコンパイラは
int型が2byte(signed short intと同じ)でした。その後32bitCPUの出現により、
そのマシン用のコンパイラではint型サイズは4byte(signed long intと同じ)になっています。
つまり、コンパイラによって型仕様の違いがあるのです。
よってこのような型の仕様はコンパイラの仕様を熟読してプログラミングしなければなりません。
なお Microsoft Visual Studio C++ 6.0 では、char が signed char、
int が signed long int と同じ扱いになっています。
よって、prinfのフォーマット文字列では、%dと%ldの指定が同じ指定となります。
なお、signedやunsignedを省略した場合は、signedの型になります。またsignedやunsignedを
記述してshortを省略した場合はintの記述が省略可能です。
(⇒unsigned k;の宣言は、unsigned int k; の宣言をしていることになります。 )
また、char型 や short型 は、処理対象になるとき 自動的に int型 へ変換されます。よって、
これらの型のデータをprintfにより10進で表示する場合、一様に%dが使えます。
また、float型は、処理対象になるとき 自動的に double型 へ変換されます。よって、
これらの型のデータをprintfにより表示する場合、一様に%fが使えます。
しかし、scanfで使うデータはこの基本データ型でなく、記憶域のアドレスを指定するので、
このような自動変換はありません。よって、char型 の場合は%c、(short int)型 の場合は%hd、
int型 や(long int)型の場合は%d、float型の場合は%f、
double型の場合は%lfと使い分ける必要があります。
(これら指定を間違えても、コンパイラのエラー指摘がないので注意が必要です。)
補足 表において%hd や%ldなど表記がありますが このhはhalf、lはlongの単語から決められた指示規則です。 これらは、C言語規則でなくprintfやscanf関数の仕様なので、 全ての開発環境で用意されているとは限りません。
補足 表において3.4e +/- 38 1.7e +/- 308の表記がありますが
これらは指数表記です。3.4e +/- 38は、3.4e-38から3.4e+38の大きさを表現で、
の範囲を意味します。
floatやdoubleは、浮動少数点の記憶方法で、
これに対応した表記が使えるわけです。例えば 123.0 と 1.23e+2 の記述は同じ値のデータを表現しているものとなります。
そしてprintfで%eを使えば、指数表現の表示が得られます。scanfの%fや%lfでは
123や123.0 や 1.23e+2 の入力が可能です。