その時、UnixのOSなどで使われるキャラクタセット"EUC_JP"で、getBytesメソッドを使ってバイト列に変換しています。
通信で、データを送受信するプログラミングはファイルの書き出しや読み取りに似ています。 そこで、以下にシンプルなバイト列での書き込みと読み取りプログラムを紹介します。
その時、UnixのOSなどで使われるキャラクタセット"EUC_JP"で、getBytesメソッドを使ってバイト列に変換しています。
01
02
03
04
05
06
07
08
09
10 11
import java.io.*;
public class EucWrite{
public static void main(String[] arg) throws Exception{
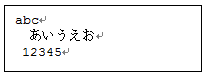
String str = "abc\r\n あいうえお\r\n 12345\r\n";
//EUCのファイル test.txtを作成
FileOutputStream fos = new FileOutputStream("euc.txt");
byte[] a = str.getBytes("EUC_JP");//"EUC_JP"のキャラクタセット使用
fos.write(a);
fos.close();
}
}
このように作成したファイルを、
Windows用メモ帳で見ても次のように正しく見えません。
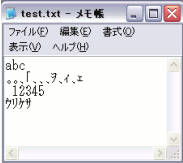
ですが、バイナリとしてLinuxへコピーすれば
Linuxで正しく見えます。
これが、『文字化け』という現象です。
Linuxでは文字コードに「EUC」を使い、Windowsでは
「ShiftJIS」を使うためです。同じ文字でも違うコード番号
になるためです。ネットワークのように、異なるオペレーションシステム間で、文字列通信を
行う場合は、相手が何のキャラクタセットで送ったかを知り、それに対応した読み取りが必要になります。上記ファイルであれば、次のプログラムで正しく表示できます。
01
02
03
04
05
06
07
08
09
10 11
12
13
14
15
16
17
import java.io.*;
class EucRead{
public static void main(String[] arg) throws Exception {
File file = new File("euc.txt");//ファイル情報を取得
int size = (int)file.length(); //ファイルサイズ長を取得 byte単位
byte[] array = new byte[size];//ファイルサイズと一致するバイト配列を用意
//ファイルから読むための入り口を管理するインスタンス取得
InputStream is = new FileInputStream(file);
is.read(array);//一括読み込み
is.close();//入り口を閉じる
//バイト列から文字列へ変換して表示
String s = new String(array,"EUC_JP");//"EUC_JP"のキャラクタセット使用
System.out.print(s);
}
}
上記の,"EUC_JP"を、"MS932"変更すると、メモ帳表示と同じような『文字化け』が確認できるでしょう。("MS932"は、Windowsで使われるキャラクタセットです。)