conda create -n win36 python=3.6 conda activate win36 pip install numpy==1.14.5 pip install matplotlib pip install japanize-matplotlib pip install pandas pip install scikit-learn pip install tensorflow==1.5.0 pip install keras==2.2.0 pip install graphviz conda install graphviz pip install pydot pip uninstall tensorflow-tensorboard ★重要 pip install tensorboard==1.6.0 ★重要なお、TensorFlow 1.5を超えるバージョンでは、Intel AVXが必須らしく、対応しないCPUでは動作しません。
この場合、「ImportError: DLL load failed: ダイナミック リンク ライブラリ (DLL) 初期化ルーチンの実行に失敗しました。」のエラーで止まります。
よって、その場合は仮想環境などで実行を整える必要があります。
keras を試す
import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist # MNISTは「エムニスト」とは、手書きで書かれた数字を画像にした画像データ(image)と、 # その画像に書かれた数字を表すラベルデータ(label)から構成されます。 ''' MNISTデータ ├ 学習用データ (60,000個) │ ├ 画像データ │ └ ラベルデータ │ └ 検証用データ (10,000個) ├ 画像データ └ ラベルデータ ''' import tensorflow as tf SEED=42 # 乱数のシード指定 np.random.seed(SEED) tf.set_random_seed(SEED) from keras.models import Sequential, load_model (X_train,y_train),(X_test,y_test) = mnist.load_data() from keras.utils.np_utils import to_categorical X_train = X_train.reshape(X_train.shape[0], 784)[:6000] X_test = X_test.reshape(X_test.shape[0], 784)[:1000] # one-hotベクトルの分類情報 y_train = to_categorical(y_train)[:6000] y_test = to_categorical(y_test)[:1000] ## モデル作成 https://keras.io/ja/getting-started/sequential-model-guide/ from keras.layers import Activation,Dense,Dropout model = Sequential() # 784個(255*255)のノードからそれぞれ256個の出力があり、次の層のノードが256個とする。 model.add(Dense(256,input_dim=784)) model.add(Activation("sigmoid")) model.add(Dense(128)) model.add(Activation("sigmoid")) model.add(Dropout(rate=0.5)) model.add(Dense(10)) model.add(Activation("softmax")) from keras import optimizers #sgd = optimizers.SGD(lr=0.1) # 学習率のハイパーパラメタ指定 #model.compile(optimizer=sgd, loss="categorical_crossentropy", metrics=["accuracy"]) model.compile(optimizer="sgd", loss="categorical_crossentropy", metrics=["accuracy"]) # 以上で作ったモデルを、以下で可視化 from keras.utils.vis_utils import plot_model import matplotlib.pyplot as plt plot_model(model,"check.png", show_layer_names=False) # モデル構造を可視化します image = plt.imread("check.png") plt.figure(dpi=150) plt.imshow(image) plt.show()
# epochs 数は 5 を指定して学習!(verbos:冗長? の指定で進捗度合いを出力させる) history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test)) ''' verbos=0とすると標準出力にログを出力しません. 1の場合はログをプログレスバーで標準出力,2の場合はエポックごとに1行のログを出力します.Train on 6000 samples, validate on 1000 samples # epochs 数は 5 を指定して学習!(verbos:冗長? の指定で進捗度合いを出力させる) ... history = model.fit(X_train, y_train, batch_size=500, epochs=5, verbose=1, validation_data=(X_test, y_test)) Train on 6000 samples, validate on 1000 samples Epoch 1/5 6000/6000 [==============================] - 1s 121us/step - loss: 2.6951 - acc: 0.1072 - val_loss: 2.3948 - val_acc: 0.1280 Epoch 2/5 6000/6000 [==============================] - 1s 87us/step - loss: 2.5092 - acc: 0.1158 - val_loss: 2.2786 - val_acc: 0.1420 Epoch 3/5 6000/6000 [==============================] - 1s 94us/step - loss: 2.4186 - acc: 0.1373 - val_loss: 2.2196 - val_acc: 0.1840 Epoch 4/5 6000/6000 [==============================] - 1s 101us/step - loss: 2.3814 - acc: 0.1345 - val_loss: 2.1806 - val_acc: 0.3120 Epoch 5/5 6000/6000 [==============================] - 1s 87us/step - loss: 2.3415 - acc: 0.1500 - val_loss: 2.1503 - val_acc: 0.4000 '''# acc、val_acc のプロットです plt.plot(history.history["acc"], label="acc", ls="-", marker="o") plt.plot(history.history["val_acc"], label="val_acc", ls="-", marker="x") plt.ylabel("accuracy") plt.xlabel("epoch") plt.legend(loc="best") # plt.show()# testデータでモデルを評価する(verbose: 進行状況メッセージ出力モード: 0 or 1) score = model.evaluate(X_test, y_test, verbose=1) '''
1000/1000 [==============================] - 0s 84us/step''' print(''' evalute loss:{0[0]} evalute acc:{0[1]} '''.format(score)) '''evalute loss:2.15030454826355 evalute acc:0.4''' probability = model.predict( X_test[10:20] ) print(probability)[[0.14415069 0.08446533 0.11078702 0.12334782 0.11395957 0.07484118 0.12660724 0.08599582 0.06163667 0.07420866] [0.12726326 0.10824199 0.0819711 0.11287815 0.13967907 0.06979022 0.11194122 0.06838155 0.08610437 0.09374905] [0.08024845 0.07635728 0.09703464 0.1017937 0.10827857 0.11351979 0.0924567 0.10579664 0.08690663 0.13760757] [0.11739478 0.09433986 0.09640167 0.08913052 0.13698903 0.07648548 0.12222236 0.10530706 0.07533531 0.0863939 ] [0.09724768 0.13787869 0.09883621 0.09311901 0.10877404 0.06132979 0.12109344 0.09385933 0.10108745 0.08677443] [0.13241273 0.08383322 0.08414117 0.11532073 0.12694813 0.08458813 0.1306643 0.08163142 0.09250057 0.0679596 ] [0.10304032 0.08552153 0.09862942 0.08368181 0.12866572 0.11008494 0.07894816 0.09331998 0.0922981 0.12581007] [0.10739273 0.07927656 0.07711172 0.11005354 0.10661541 0.09210152 0.09112577 0.12841484 0.08255335 0.12535456] [0.09595173 0.09807979 0.11927406 0.12386177 0.10985649 0.08140141 0.10174388 0.1001775 0.08864204 0.08101133] [0.09146903 0.07420243 0.08500359 0.12064636 0.1303262 0.10547653 0.10356725 0.0898888 0.07774256 0.12167726]]pred = np.argmax(probability, axis=1) print(pred)# [0 4 9 4 1 0 4 7 3 4]# X_test[10:20] のデータを上記で群類判定したが、そのテスト対象を視覚化する。 for i in range(10): plt.subplot(1,10, i+1) plt.imshow(X_test[10+i].reshape((28,28)), "gray") plt.show() #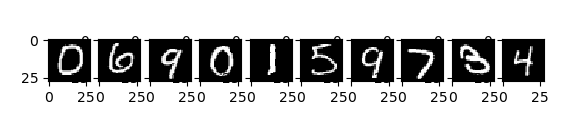
活性化関数で使われるもの
Activation("sigmoid")
Activation("relu")⇒Rectified Linear Unit(正規化線形ユニット)
アルゴリズムで使われるもの
optimizer="sgd" ⇒Stochastic Gradient Descent 確率的勾配降下法
optimizer="adam" ⇒Adaptive Moment Estimation 直近の勾配情報を利用
optimizer=RMSprop()