import tensorflow as tf
# 引数からテンソル定数を生成してテンソルを返す関数を定義
# a * a + b に相当するオペレーションを返す。
def a_X_a_plus_b(a, b):
_a = tf.constant(a, name = "a") # aの値で、"a"の名前でTensorを作る
print("_a.name", _a.name) # Tensorの名前の確認
_b = tf.constant(b)
_op = tf.square(_a) # 2乗にする。
print("_r.name", _op.name) # Tensorの名前の確認
_op = tf.add(_op, _b) # 上記にbを加算
print("_r.name", _op.name) # Tensorの名前の確認
return _op;
sess = tf.Session()
a=5
b=1
c = sess.run(a_X_a_plus_b(a, b))
#_a.name a:0
#_r.name Square:0
#_r.name Add:0
print("a_X_a_plus_b(5,1)=",c, "が結果で、型:" , type(c) )
#a_X_a_plus_b(5,1)= 26 が結果で、型: <class 'numpy.int32'>
a=[1,2,3,4,5,6]
c = sess.run(a_X_a_plus_b(a, b))
#_a.name a_1:0
#_r.name Square_1:0
#_r.name Add_1:0
print("a_X_a_plus_b(",a,",",b,")=",c)
#a_X_a_plus_b( [1, 2, 3, 4, 5, 6] , 1 )= [ 2 5 10 17 26 37]
b=[1,2,3,4,5,6]
c = sess.run(a_X_a_plus_b(a, b))
#_a.name a_2:0
#_r.name Square_2:0
#_r.name Add_2:0
print("a_X_a_plus_b(",a,",",b,")=",c)
#a_X_a_plus_b( [1, 2, 3, 4, 5, 6] , [1, 2, 3, 4, 5, 6] )= [ 2 6 12 20 30 42]
sess.close();
import write_graph
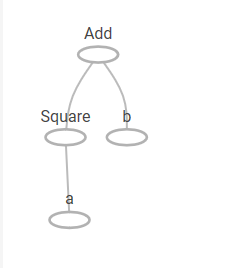
この計算グラフを以下に示します。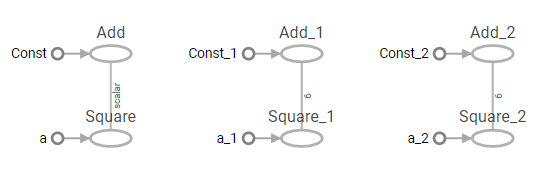
上記において、関数「a_X_a_plus_b」を、3回使って計算させている例であるが、 関数内部で、定数や関数のTensorが作られているのが分かる。
Tensor.nameの表示で、例えば定数で a の名前で作るようにしていますが、 関数実行ごとに生成しているので、 a_1、 a_2 の名前が生成されている。
a同様にSquareやAddのオペレーションテンソルも複数存在している。
こんな余計なリソースを使うコードは正しくないはず である。 そこで、どう作るべきか検討した。
この検討した結論を示します。(分かりにくいので始めに書きました)
余計なリソースができるようにも見えますが、
「a,bの入力がスカラー、一次元リスト、2次元 リスト対応して効率的に動作できる関数の実現自体がすごいこと」
という結論です。
上記で3つできた「計算グラフ」はそれぞれの入力に対する計算式の構造を生成して、動作できていること自体が重要なことです。
tensorflowに慣れている方には、当たり前かもしれませんが、この結論に達するまでに、色々と意味がないかもしれない以下のような検証をしました。
別の手法の検討として、リソースを減らせるかも?という検討で、引数aを記憶する_aのテンソルを関数の外側で作り、それを参照することで 動作するように関数「a_X_a_plus_b」を作り変えてみました。
それは、get_variableを使った共有変数を利用する方法で、次の失敗例です。
import tensorflow as tf
with tf.variable_scope("myscope1"): # 共有変数var1を、外部であらかじめ作成する。
varA = tf.get_variable("var1", initializer=0)
# a * a + b に相当するオペレーションを返す。(aを共有変数var1にセット、bは定数にセット)
def a_X_a_plus_b(a, b):
with tf.variable_scope("myscope1", reuse=True):
varA = tf.get_variable("var1",dtype=tf.int32) # 共有変数var1を参照する。
#
#_a = tf.constant(a, name = "a") # この定数の代わりに変数を使う試み
_a = tf.assign(varA, a, name="a") # 共有変数var1に仮引数aを設定して使う。
_b = tf.constant(b)
_op = tf.square(_a) # 2乗にする。
_op = tf.add(_op, _b) # 上記にbを加算
return _op;
sess = tf.Session()
sess.run(tf.global_variables_initializer())# 変数を使う場合、セッションでこの初期化処理が必要です。
c = sess.run(a_X_a_plus_b(5, 1))
print("a_X_a_plus_b(5,1)=",c, "が結果" )#a_X_a_plus_b(5,1)= 26 が結果
c = sess.run(a_X_a_plus_b(2, 3))
print("a_X_a_plus_b(2,3)=",c, "が結果" )#a_X_a_plus_b(2,3)= 7 が結果
c = sess.run(a_X_a_plus_b(2, [1,2,3,4,5,6]))
print(c, "が結果")#[ 5 6 7 8 9 10] が結果
なお、sess.run(a_X_a_plus_b( [1,2,3,4,5,6] , 2))のように、第1引数にリストを使うと次の実行エラーです。「ValueError: Shapes must be equal rank, but are 0 and 1 for 'Assign_3' (op: 'Assign') with input shapes: [], [6].」
これは、共有変数がdtype=tf.int32になって型が違うためです。
そこで、第1引数に6要素のリストを指定できるように変更した次のコードも作ってみました。
import tensorflow as tf
with tf.variable_scope("myscope1"): # 共有変数var1を、外部であらかじめ作成する。
varA_init = tf.constant_initializer( [0])
varA = tf.get_variable("var1", shape=[6], initializer=varA_init )
# a * a + b に相当するオペレーションを返す。(aを共有変数var1にセット、bは定数にセット)
def a_X_a_plus_b(a, b):
with tf.variable_scope("myscope1", reuse=True):
varA = tf.get_variable("var1", shape=[6]) # 共有変数var1を参照する。
#
#_a = tf.constant(a, name = "a") # この定数の代わりに変数を使う試み
_a = tf.assign(varA, a, name="a") # 共有変数var1に仮引数aを設定して使う。
_b = tf.constant(b , dtype=tf.float32)
_op = tf.square(_a) # 2乗にする。
_op = tf.add(_op, _b) # 上記にbを加算
return _op;
sess = tf.Session()
sess.run(tf.global_variables_initializer())# 変数を使う場合、セッションでこの初期化処理が必要です。
c=sess.run(a_X_a_plus_b( [1,2,3,4,5,6] , 2))
print(c, "が結果") # [ 3. 6. 11. 18. 27. 38.] が結果
c = sess.run(a_X_a_plus_b([1,2,3,4,5,6], [1,2,3,4,5,6]))
print(c, "が結果") # [ 2. 6. 12. 20. 30. 42.] が結果
#c = sess.run(a_X_a_plus_b(2, [1,2,3,4,5,6]))を行うと、次の実行エラー
# ValueError: Shapes must be equal rank, but are 1 and 0 for 'a_2' (op: 'Assign') with input shapes: [6], [].
これで、第1引数に6要素のリストを指定できるようになったが、6要素のリスト以外を与えると実行エラーとなります。なお、他にも「tf.add(_op, _b) 」で次のエラーがで発生し、これに対して「dtype=tf.float32」の引数を追加して対応した。
「TypeError: Input 'y' of 'Add' Op has type int32 that does not match type float32 of argument 'x'. 」
これは、 print( _a)の確認で「Tensor("Assign:0", shape=(6,), dtype=float32_ref)」が得られ、 print( _op)の確認で「Tensor("Square:0", shape=(6,), dtype=float32))」が得られることから それに対応すると、_b生成で「dtype=tf.float32」の引数が必要と考えて、追加した。
この計算グラフを以下に示します。
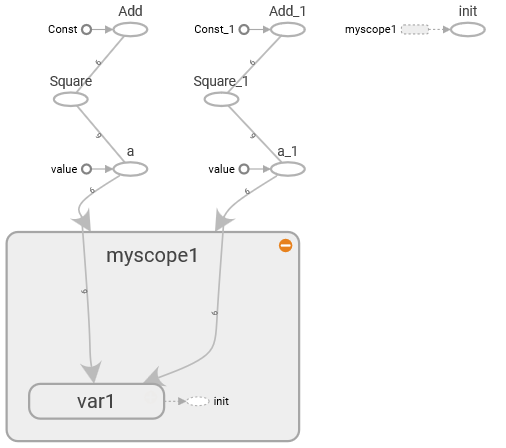
myscope1の名前空間でvar1の共有変数を用意して、 a_X_a_plus_bを2回実行することで引数を共有変数var1に割り当てるassinの演算、それのSqure演算、 これと引数bのConstをAddする演算が、それぞれ2回分生成されているのが分かる。
名前空間と共有変数を理解する助けにはなったが、最初の構造に対して、引数aの使える範囲が6要素のリストに限定されて、 使いにくい関数になってしまった。
次にa,bの引数のように、後から計算グラフに情報を与えて実行する場合、プレースホルダを使うべきでは?と考えて それを使う関数「a_X_a_plus_b」に変更してみた。
そのプレースホルダを使ったコードを以下にします。
# -*- coding: utf-8 -*-
import tensorflow as tf
# a * a + b に相当するオペレーションを返す。(aを共有変数var1にセット、bは定数にセット)
def a_X_a_plus_b():
_a = tf.placeholder(tf.int32, name='a')
_b = tf.placeholder(tf.int32, name='b')
_op = tf.square(_a) # 2乗にする。
_op = tf.add(_op, _b) # 上記にbを加算
return _a, _b, _op;
with tf.Session() as sess:
_a, _b, op = a_X_a_plus_b();
v = sess.run(op , feed_dict={_a: 5, _b: 1})
print(v) # 実行結果:26
v = sess.run(op , feed_dict={_a: [1,2,3,4,5,6], _b: 1})
print(v) # 実行結果:[ 2 5 10 17 26 37]
v = sess.run(op , feed_dict={_a: [1,2,3,4,5,6], _b: [1,2,3,4,5,6]})
print(v) # 実行結果:[ 2 6 12 20 30 42]
import write_graph
この計算グラフを以下に示します。この仕様において、最も効率的に動作する適切なコードと言えます。